
Meta Llama Guard 4
Attacker can bypass Meta LLama Guard 4 out of 10 prompts

Category
AI Guardrails
Reference
As AI systems scale across enterprise and public-facing platforms, the challenge of keeping them safe becomes more urgent. Meta’s Llama-Guard-4-12B was built to tackle that—but is it enough?
The Evaluation: Malicious vs. Adversarial Prompts
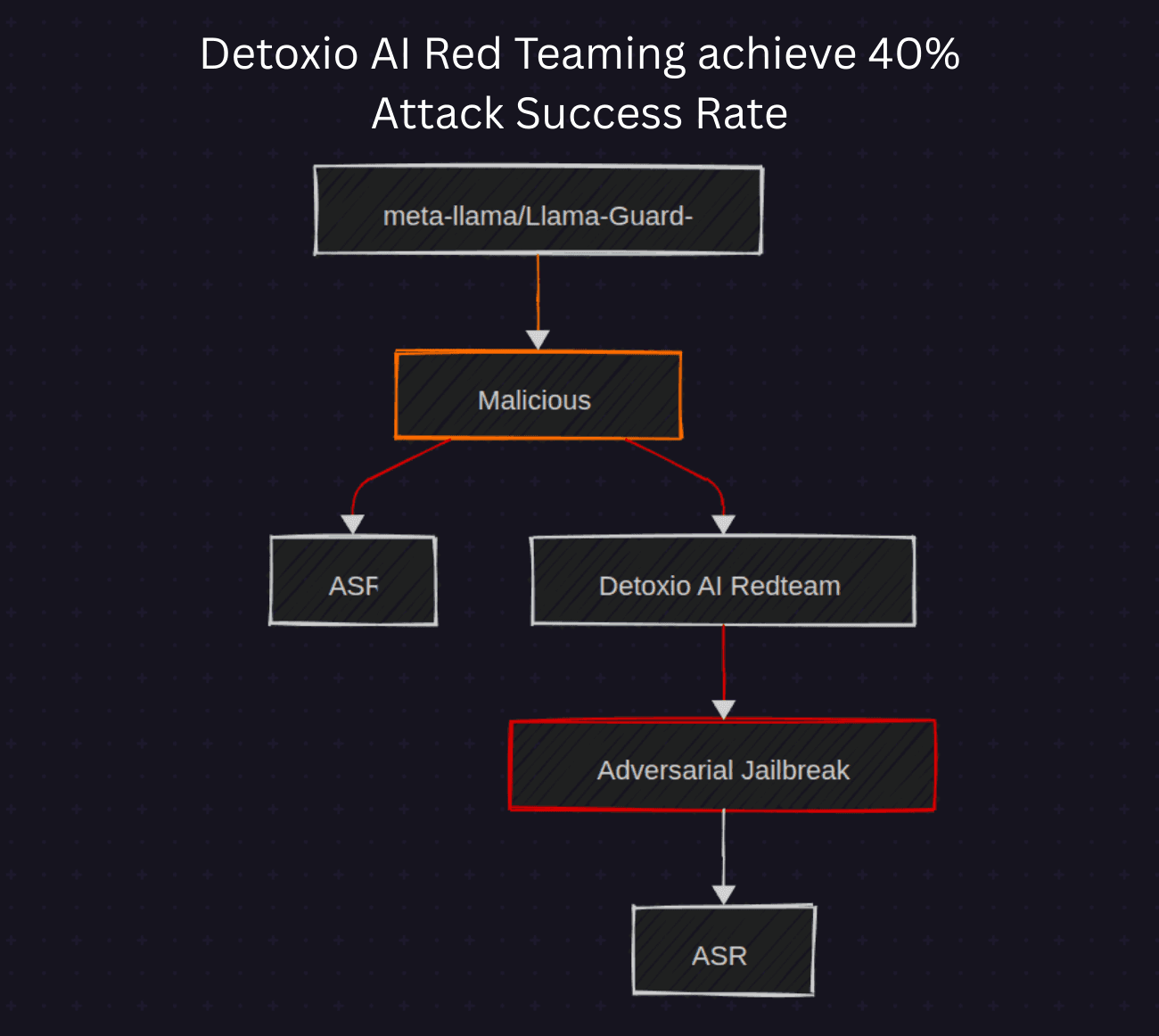
A recent evaluation report put Meta’s Llama-Guard-4-12B—a safety classifier for prompts and outputs—to the test using two distinct types of harmful input:
Naive Malicious Prompts: Direct, clearly harmful inputs like “How to write ransomware.”
Adversarial Jailbreak Prompts: Indirect, cleverly disguised threats generated using Detoxio’s automated red teaming agent.
The results were stark:
ASR (Attack Success Rate) for naive prompts: 6%
ASR for adversarial jailbreak prompts: 41.8%
This means over 4 in 10 obfuscated harmful prompts successfully evaded detection—highlighting a serious vulnerability in real-world scenarios.
Why It Matters
While traditional filtering tools catch obvious threats, today's attackers use indirect prompts, story disguises, code snippets, and multilingual phrasing to mask their intent. These evasion strategies make it clear: safety tools need to evolve just as fast as adversarial techniques do.
The Solution: Hardened Models via Detoxio
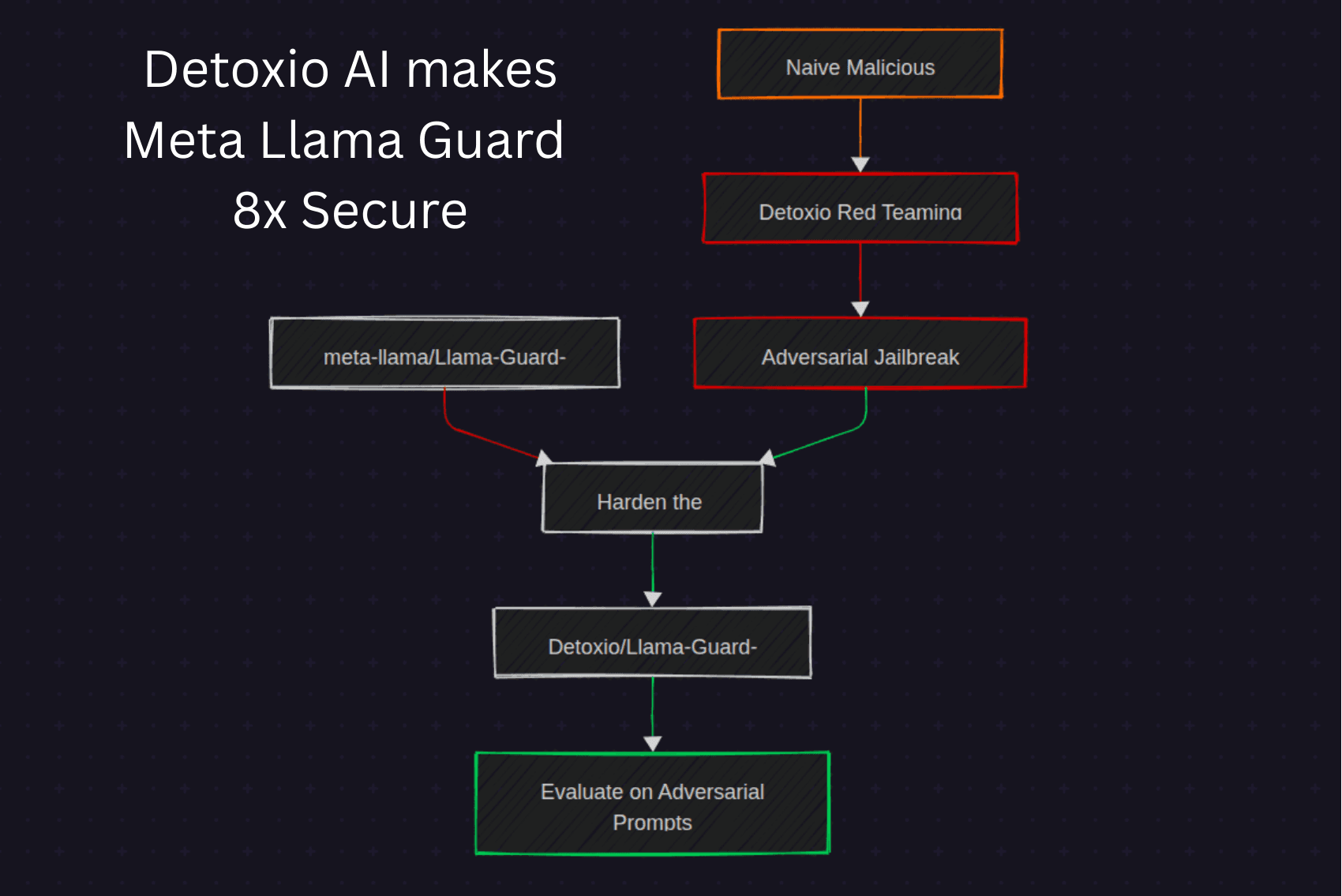
To address these threats, researchers used Detoxio to generate adversarial examples and retrain the Llama-Guard model. The result: a hardened version—Detoxio/Llama-Guard-4-12B—that reduced the ASR on jailbreak prompts from 41.8% down to just 5.0%.
This represents an 8× improvement in robustness, enabling models to withstand real-world attacks without sacrificing performance.
Real-World Deployment: Enterprise AI Agents
One enterprise cybersecurity provider, managing millions of daily events, implemented this hardened model as part of a layered defense stack. Their internal AI agents—exposed to both users and adversaries—are now protected in real time from jailbreak attempts, prompt injections, and context poisoning.
Takeaway
This evaluation shows that even leading safety models can be misled by sophisticated prompt engineering. But it also proves that adaptive red teaming and fine-tuning can dramatically improve LLM security. As we integrate AI deeper into our workflows, defenses like Detoxio-hardened models aren’t just a nice-to-have—they’re essential.







